Twitter was buzzing, or something, this morning, with the news that Amazon is going to change the commission rates that it charges researchers who use Mechanical Turk (henceforth: MTurk) participants to take surveys, quizzes, personality tests, etc.
(This blog post contains some MTurk jargon. My previous post was way too long because I spent too much time summarising what someone else had written, so if you don't know anything about MTurk concepts, read this.)
The changes to Amazon's rates, effective July 21, 2015, are listed here, but since that page will probably change after July, I took a screenshot:
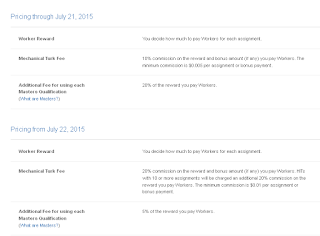
Here's what this means. Currently, if you hire 100 people to fill in your survey and want to give them $1 each, you pay Amazon $110 for "regular" workers and $130 for "Masters". Under the new pricing scheme, this will be $140 and $145, respectively. That's an increase of 27.3% and 11.5%, respectively. (I'm assuming, first, that the wording about "10 or more assignments" means "10 or more instances of the HIT being executed, not necessarily by the same worker", and second, that any psychological survey will need more than 10 assignments.)
Twitter users were quite upset about this. Someone portrayed this as a "400% increase", which is either a typo, or a miscalculation (Amazon's commission for "regular" workers is going from 10% to 40%, which even expressed as "$10 to $40 on a $100 survey" is actually a 300% increase), or a misunderstanding (the actual increase in cost for the customer is noted in the previous paragraph). People are talking of using this incident as a reason to start a new, improved platform, possibly creating an international participant pool.
Frankly, I think there is a lot of heat and not much light being generated here.
First, researchers are going to have to face up to the fact that by using MTurk, they are typically exploiting sub-minimum wage labour. (There are, of course, honourable exceptions, who try to ensure that online survey takers are fairly remunerated.) The lowest wage rate I've personally seen in the literature was a study that paid over 100 workers the princely sum of $0.25 each for a task that took 20 minutes to complete. Either those people are desperately poor, or they are children looking for pocket money, or they are people who just really, really like being involved in research, to an extent that might make some people wonder about selection bias.
I have asked researchers in the past how they felt about this exploitation, and the standard answer has been, "Well, nobody's forcing them to do it". The irony of social psychologists --- who tend not to like it when someone points out that they overwhelmingly self-identify as liberal and this is not necessarily neutral for science --- invoking essentially the same arguments as exploitative corporations for not paying people adequately for their time, is wondrous to behold. (It's not unique to academia, though. I used to work at an international organisation, dedicated to human rights and the rule of law, where some managers who made six-figure tax-free salaries were constantly looking for ways to get interns to do the job of assistants, or have technical specialists agree to work for several months for nothing until funding "maybe" came through for their next contract.)
Second, I have doubts about the validity of the responses from MTurk workers. Some studies have shown that they can perform as well as college students, although maybe it's best to take on the "Master"-level workers, whose price is only going up 11.5%; and I'm not sure that college students ought to be regarded as the best benchmark [PDF] here. But there are technical problems, such as issues with non-independence of data [PDF] --- if you put three related surveys out there, there's a good chance that many of the same people may be answering them --- and the population of MTurk workers is a rather strange and unrepresentative bunch of people; the median participant in your survey has already completed 300 academic tasks, including 20 in the past week. One worker completed 830,000 MTurk HITs in 9 years; if you don't want to work out how many minutes per HIT that represents assuming she worked for 16 hours a day, 365 days a year, here's the answer. Workers are overwhelmingly likely to come from one of just two countries, the USA and India, presumably because those are the countries where you can get paid in real cash money; MTurk workers in other countries just get credit towards an Amazon gift card (which, when I tried to use it, could only be redeemed on the US site, amazon.com, thus incurring shipping and tax charges when buying goods in Europe). Maybe this is better than having your participants being all from just one country, but since you don't know what the mix of countries is (unless you specify that the HIT will only be shown in one country), you can't even make claims about the degree of generalisability of your results.
Third, this increase really does not represent all that much money. If you're only paying $33 to run 120 participants at $0.25, you can probably afford to pay $42. That $9 increase is less than you'll spend on doughnuts at the office mini-party when your paper gets accepted (but it won't go very far towards building, running, and paying the electricity bill for your alternative, post-Amazon solution). And let's face it, if these commission rates had been in place from the start, you'd have paid them; the actual increase is irrelevant, just like it doesn't matter when you pay $20 for shipping on a $2 item from eBay if the alternative is to spend $30 with "free" shipping. All those people tweeting "Goodbye Amazon" aren't really going to switch to another platform. At bottom, they're just upset because they discovered that a corporation with a monopoly will exploit it, as if they really, really thought that things were going to be different this time (despite everyone knowing that Amazon abuses its warehouse workers and has a history of aggressive tax avoidance). Indeed, the tone of the protests is remarkable for its lack of direct criticism of Amazon, because that would require an admission that researchers have been complicit with its policies, to an extent that I would argue goes far beyond the average book buyer. (Disclosure: I'm a hypocrite who orders books or other goods from Amazon about four times a year. I have some good and more bad justifications for that, but basically, I'm not very political, the points made above notwithstanding.)
Bottom line: MTurk is something that researchers can, and possibly (this is not a blog about morals) "should", be able to do without. Its very existence as a publicly available service seems to be mostly a matter of chance; Amazon doesn't spend much effort on developing it, and it could easily disappear tomorrow. It introduces new and arguably unquantifiable distortions into research in fields that already have enough problems with validity. If this increase in prices led to people abandoning it, that might be a good thing. But my guess is that they won't.
Acknowledgement: Thanks to @thosjleeper for the links to studies of MTurk worker performance.
(This blog post contains some MTurk jargon. My previous post was way too long because I spent too much time summarising what someone else had written, so if you don't know anything about MTurk concepts, read this.)
The changes to Amazon's rates, effective July 21, 2015, are listed here, but since that page will probably change after July, I took a screenshot:

Here's what this means. Currently, if you hire 100 people to fill in your survey and want to give them $1 each, you pay Amazon $110 for "regular" workers and $130 for "Masters". Under the new pricing scheme, this will be $140 and $145, respectively. That's an increase of 27.3% and 11.5%, respectively. (I'm assuming, first, that the wording about "10 or more assignments" means "10 or more instances of the HIT being executed, not necessarily by the same worker", and second, that any psychological survey will need more than 10 assignments.)
Twitter users were quite upset about this. Someone portrayed this as a "400% increase", which is either a typo, or a miscalculation (Amazon's commission for "regular" workers is going from 10% to 40%, which even expressed as "$10 to $40 on a $100 survey" is actually a 300% increase), or a misunderstanding (the actual increase in cost for the customer is noted in the previous paragraph). People are talking of using this incident as a reason to start a new, improved platform, possibly creating an international participant pool.
Frankly, I think there is a lot of heat and not much light being generated here.
First, researchers are going to have to face up to the fact that by using MTurk, they are typically exploiting sub-minimum wage labour. (There are, of course, honourable exceptions, who try to ensure that online survey takers are fairly remunerated.) The lowest wage rate I've personally seen in the literature was a study that paid over 100 workers the princely sum of $0.25 each for a task that took 20 minutes to complete. Either those people are desperately poor, or they are children looking for pocket money, or they are people who just really, really like being involved in research, to an extent that might make some people wonder about selection bias.
I have asked researchers in the past how they felt about this exploitation, and the standard answer has been, "Well, nobody's forcing them to do it". The irony of social psychologists --- who tend not to like it when someone points out that they overwhelmingly self-identify as liberal and this is not necessarily neutral for science --- invoking essentially the same arguments as exploitative corporations for not paying people adequately for their time, is wondrous to behold. (It's not unique to academia, though. I used to work at an international organisation, dedicated to human rights and the rule of law, where some managers who made six-figure tax-free salaries were constantly looking for ways to get interns to do the job of assistants, or have technical specialists agree to work for several months for nothing until funding "maybe" came through for their next contract.)
Second, I have doubts about the validity of the responses from MTurk workers. Some studies have shown that they can perform as well as college students, although maybe it's best to take on the "Master"-level workers, whose price is only going up 11.5%; and I'm not sure that college students ought to be regarded as the best benchmark [PDF] here. But there are technical problems, such as issues with non-independence of data [PDF] --- if you put three related surveys out there, there's a good chance that many of the same people may be answering them --- and the population of MTurk workers is a rather strange and unrepresentative bunch of people; the median participant in your survey has already completed 300 academic tasks, including 20 in the past week. One worker completed 830,000 MTurk HITs in 9 years; if you don't want to work out how many minutes per HIT that represents assuming she worked for 16 hours a day, 365 days a year, here's the answer. Workers are overwhelmingly likely to come from one of just two countries, the USA and India, presumably because those are the countries where you can get paid in real cash money; MTurk workers in other countries just get credit towards an Amazon gift card (which, when I tried to use it, could only be redeemed on the US site, amazon.com, thus incurring shipping and tax charges when buying goods in Europe). Maybe this is better than having your participants being all from just one country, but since you don't know what the mix of countries is (unless you specify that the HIT will only be shown in one country), you can't even make claims about the degree of generalisability of your results.
Third, this increase really does not represent all that much money. If you're only paying $33 to run 120 participants at $0.25, you can probably afford to pay $42. That $9 increase is less than you'll spend on doughnuts at the office mini-party when your paper gets accepted (but it won't go very far towards building, running, and paying the electricity bill for your alternative, post-Amazon solution). And let's face it, if these commission rates had been in place from the start, you'd have paid them; the actual increase is irrelevant, just like it doesn't matter when you pay $20 for shipping on a $2 item from eBay if the alternative is to spend $30 with "free" shipping. All those people tweeting "Goodbye Amazon" aren't really going to switch to another platform. At bottom, they're just upset because they discovered that a corporation with a monopoly will exploit it, as if they really, really thought that things were going to be different this time (despite everyone knowing that Amazon abuses its warehouse workers and has a history of aggressive tax avoidance). Indeed, the tone of the protests is remarkable for its lack of direct criticism of Amazon, because that would require an admission that researchers have been complicit with its policies, to an extent that I would argue goes far beyond the average book buyer. (Disclosure: I'm a hypocrite who orders books or other goods from Amazon about four times a year. I have some good and more bad justifications for that, but basically, I'm not very political, the points made above notwithstanding.)
Bottom line: MTurk is something that researchers can, and possibly (this is not a blog about morals) "should", be able to do without. Its very existence as a publicly available service seems to be mostly a matter of chance; Amazon doesn't spend much effort on developing it, and it could easily disappear tomorrow. It introduces new and arguably unquantifiable distortions into research in fields that already have enough problems with validity. If this increase in prices led to people abandoning it, that might be a good thing. But my guess is that they won't.
Acknowledgement: Thanks to @thosjleeper for the links to studies of MTurk worker performance.


